網管人雜誌
本文刊載於 網管人雜誌第 117 期 - 2015 年 10 月 1 日出刊,NetAdmin 網管人雜誌為一本介紹 Trend Learning 趨勢觀念、Solution Learning 解決方案、Technology Learning 技術應用的雜誌,下列筆記為本站投稿網管人雜誌獲得刊登的文章,網管人雜誌於每月份 1 日出刊您可於各大書店中看到它或透過下列圖示連結至博客來網路書店訂閱它。文章目錄
1、前言2、S2D 技術有何不同?
採用 S2D 技術有何好處?
S2D 技術的運作架構
S2D 技術的部署模式
S2D 技術的資料存放原則及容錯機制
S2D 技術的容錯機制
3、S2D 實戰 – 硬體需求
安裝 Windows Server 2016 TP2 或 TP3
安裝 Hyper-V 並建立虛擬交換器
安裝 Windows Server 角色及功能
建立 SOFS 容錯移轉叢集
啟用 Storage Spaces Direct 機制
建立 Storage Pool、Virtual Disk、Volume
建立 SOFS 高可用性角色
建立 SOFS 檔案分享資源
4、結語
1、前言
Windows Server vNext 為目前 Windows Server 2016 先前的開發名稱,並在 2014 年 10 月 1 日時正式發佈「技術預覽 (Technical Preview,TP)」版本,接著在 2015 年 5 月 4 日發佈 TP2 技術預覽版本。最新版本,則是在 2015 年 8 月 19 日發佈的 TP3 技術預覽版本。在 Windows Server 2016 TP2 技術預覽版本中,導入許多新的特色功能如 Nano Server、Storage Replica、PowerShell DSC (Desired State Configuration)…等技術。至於,最新版本的 Windows Server 2016 TP3 技術預覽版本中,則主要是新增了 Windows Server Containers 技術在裡面。
本文,要向大家介紹及實作的微軟「軟體定義儲存 (Software-Defined Storage,SDS)」技術,則是內含在 Windows Server 2016 TP2 技術預覽版本當中,它是由 Windows Server 2012 R2 當中的「Storage Space」技術演化而來,在 Windows Server 2016 當中稱之為「Storage Spaces Direct (S2D)」。
事實上,目前的微軟 SDS 技術名稱 Storage Spaces Direct,在 Windows Server vNext 開發時期稱之為「Storage Spaces Shared Nothing」。
2、S2D技術有何不同?
首先,大家一定對於 Windows Server 2016 當中 S2D 軟體定義儲存技術感到好奇,並且極想了解它與 Windows Server 2012 R2 當中的 Storage Space 技術有何不同。簡單來說,最主要的關鍵在於 S2D 技術,可以將多台伺服器的「本機硬碟 (Local Disk)」結合成為一個大的儲存資源池。在 Windows Server 2012 R2 當中的 Storage Space 技術,底層的儲存資源是採用「共享式JBOD (Shared JBOD)」的方式,將多座 JBOD 結合成為一個大的儲存資源池。然後,再透過其上的 SOFS (Scale-Out File Server)叢集節點,將掛載的 JBOD 儲存資源,透過 SMB 3.0 協定將儲存資源分享給 Hyper-V 容錯移轉叢集。

圖 1、Windows Server 2012 R2 Storage Space 技術運作示意圖
在 Windows Server 2016 TP2 當中的 S2D 技術,則可以直接將原本的 SOFS (Scale-Out File Server) 叢集節點主機中「本機硬碟 (Local Disk)」,透過 RDMA 網路環境將多台 SOFS 叢集節點的本機硬碟資源,結合成為一個大的儲存資源,然後透過 SMB 3.0 協定將儲存資源分享給 Hyper-V 容錯移轉叢集。

圖 2、Windows Server 2016 TP2 S2D(Storage Space Direct) 技術運作示意圖
採用 S2D 技術有何好處?
首先.採用 S2D 技術對於企業或組織的 IT 管理人員來說,最大的好處便是「簡化部署」。因為,採用 S2D 技術之後可以拋開傳統複雜的 SAS 網狀架構 (採用 JBOD 架構的副作用),改為採用相對單純的網路架構即可。此外,因為省去了 JBOD 硬碟機箱,連帶節省大量的機櫃空間、電力、冷氣…等,這也是額外帶來的效益。因此,現在企業或組織的 IT 管理人員除了不用規劃及組態設定 SAS Cabling 事宜外,也不用安裝及設定 MPIO 多重路徑機制。

圖 3、Windows Server 2012 R2 Storage Space with Shared JBODs 運作示意圖
另一項好處則是可以「無縫式進行擴充」,簡單來說可以達成「水平擴充 (Scale-Out)」的運作架構。現在,IT 管理人員只要增加 SMB 容錯移轉叢集架構中的叢集節點,即可同時增加整體的「儲存空間」以及「傳輸速率」,並且新加入的叢集節點將會自動進行儲存資源的負載平衡作業。

圖 4、Windows Server 2016 TP2 Storage Spaces Direct with Internal Disks 運作示意圖
當然,若企業或組織已經建置 Windows Server 2012 R2 的共享式 JBOD 架構的話,那麼在 Windows Server 2016 當中的 S2D 技術,除了支援本機硬碟成為儲存資源池之外,也支援原有的共享式 JBOD 架構,讓企業或組織可以輕鬆將共享式 JBOD 運作架構,由原本的 Windows Server 2012 R2 升級為 Windows Server 2016。

圖 5、Windows Server 2016 TP2 Storage Spaces Direct with JBOD 運作示意圖
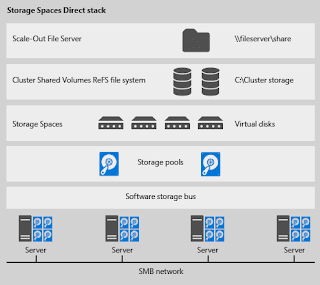
S2D 技術的運作架構
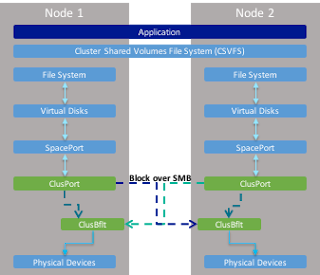
在 S2D 軟體定義儲存技術中,整個運作架構包含了 SOFS (Scale-Out File Server)、CSVFS (Clustered Shared Volume File System)、Storage Spaces、Failover Clustering等技術。那麼,讓我們來看看在相關運作層級中,每個層級所專司的運作角色以及功能為何。Network:在 S2D 運作架構中,每台 SMB 叢集節點主機是透過支援「RDMA (Remote Direct Memory Access)」功能的網路卡,進行資料傳輸作業。透過採用支援 RDMA 功能的網路卡,可以有效讓 SMB 叢集節點主機能夠達到「高輸送量 (High Throughput)、低延遲 (Low Latency)、低 CPU 使用率 (Low CPU Utilization)」,也就是不會對 SMB 叢集節點主機造成效能影響。
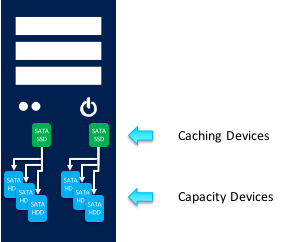
Storage Node: S2D 運作架構至少要由「4台」SMB叢集節點主機所組成,每台節點主機可以採用本機硬碟或共享式 JBOD,至於硬碟的支援度部分除了可以採用 SAS/NL-SAS/SATA 之外,還支援新一代的 NVMe(NVM Express)。
Software Storage Bus:微軟便是透過此「軟體儲存匯流排 (Software Storage Bus)」技術,將眾多 SMB 叢集節點主機當中的本機硬碟,串連成為一個大的儲存資源池,也就是讓所有的硬碟可以座落在同一個 Storage Spaces Layer 之上。
Storage Pool:這是原本在 Windows Server 2012 R2 當中 Storage Spaces 的技術。簡單來說,底層已經透過 Software Storage Bus 技術,將眾多 SMB 叢集節點主機的本機硬碟串連成儲存資源池,接著便可以透過 Storage Pool 技術,針對不同的硬碟介面或顆數進行儲存資源池的建立作業。
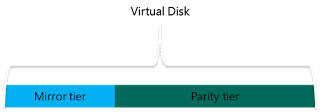
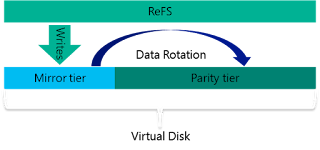
Virtual Disks:當建立好 Storage Pool 儲存資源池作業後,便可以建立「虛擬磁碟 (Virtual Disks)」。此時,便可以決定硬碟的容錯等級,例如,採用 2-Way / 3-Way Mirror 方式,以便兼顧硬碟運作效能的同時還能保有資料容錯的特性。
CSVFS:在 S2D 運作架構中,並非採用舊有的 NTFS 檔案系統,而是採用新一代的 ReFS v2檔案系統,並且針對 Storage Space 機制進行優化處理,除了具備 Error Detection、Automatic Correction 機制之外,還針對 VHD/VHDX(Fixed、Dynamic、Merge) 格式進行「加速(Accelerations)」處理。
SOFS:將底層的儲存資源池及高可用性機制處理完成後,最後便是透過「SOFS (Scale-Out File Server)」機制,將儲存資源分享給 VM 虛擬主機、SQL Server...等使用。

圖 6、Windows Server 2016 TP2 Storage Spaces Direct 運作架構示意圖
S2D 技術的部署模式
那麼,我們來看看S2D軟體定義儲存技術有哪些部署模式,以便稍後進行實作時不致發生觀念混亂的情況。在S2D技術中支援兩種部署模式:- 超融合式 (Hyper-Converged)。
- 「融合式 (Converged)」或稱「分類 (Disaggregated)」。
首先,如果採用「超融合式(Hyper-Converged)」部署模式的話,那麼便是將「運算 (Compute)、儲存 (Storage)、網路 (Network)」等資源全部「整合」在一起,適合用於中小型規模的運作架構。

圖 7、S2D 超融合式部署模式運作示意圖
如果,採用「融合式(Converged)」部署模式的話,那麼便是將「運算 (Compute)、儲存 (Storage)、網路 (Network)」等資源全部「分開」進行管理,適合用於中大型規模的運作架構。

圖 8、S2D 融合式部署模式運作示意圖
S2D 技術的資料存放原則及容錯機制
S2D 運作架構在資料存放原則的部分,與過去 Windows Server 2012 R2 稍有不同,最明顯的部分便是「Extent」。現在,建立的 虛擬磁碟(Virtual Disk)其實是由眾多的 Extent 所組成,每個 Extent 的單位大小為「1 GB」,舉例來說,100 GB 大小的虛擬磁碟便是由 100 個 Extent 所組成。因此,當儲存資源池及虛擬磁碟建立完畢後,便會產生許多 Extent 並且會自動擺放在不同的 SMB 叢集節點主機當中。此外,假設虛擬磁碟為 100 GB 大小所以會有 100 個 Extents,當我們採用 3-Way Mirror 容錯機制時(所以會有 300 個 Extents),那麼系統便會確保第 2、3 份 Extent 擺放在不同台 SMB 叢集節點主機當中,以便因應後續如硬碟故障、SMB 叢集節點主機...等故障損壞事件。

圖 9、S2D 資料存放原則運作示意圖
S2D 技術的容錯機制
當 S2D 軟體定義儲存技術,在達成簡單部署及磁碟效能的同時,當然還要兼顧到資料的容錯機制。在資料的容錯機制方面,它可以有效因應「硬碟 (Hard Disk)、機箱 (Enclosure)、伺服器 (Server)」等發生故障損壞事件。先前已經提到,S2D 技術最少必須由「4台」叢集節點組合而成,在這樣的運作架構下可以建立 3-Way Mirror 機制,並且可以容許「2台」叢集節點發生故障並且也支援容錯分區機制,也就是說可以支援資料的「放置、修復、重建、負載平衡」等機制,讓線上存取資料的動作能夠不被故障事件所影響並持續運作。

圖 10、S2D 容錯機制運作示意圖
3、S2D 實戰 – 硬體需求
那麼,讓我們來看看若企業或組織的IT管理人員,若要搶先體驗及建置 S2D 軟體定義儲存技術的話,該如何建構 S2D 測試環境:節點主機:最少必須由 4 台節點主機組成。在 Windows Server 2016 TP2 版本時最多支援 12 台伺服器,在 2016 TP3 版本時最多支援 16 台伺服器。
硬碟控制器:每台節點主機,應該採用 SATA Connected 或 SAS HBA Connected 的連接方式,而非使用 ACHI Controller 或 RAID Controller 的方式。
硬碟數量:每台節點主機,最少應該使用 1 顆 SSD 固態硬碟及 1 顆機械式硬碟。
網路卡:每台節點主機,最少應該使用 1 Port 10GbE 網路,並且必須支援 RDMA 特色功能 (RoCE、iWARP、InfiniBand),目前支援的網路卡廠商有 Mellanox (CX3-Pro)、Chelsio (T5)、Avago/Emulex (Skyhawk)...等。
此外,值得注意的部分是,請只採用 PowerShell來進行 S2D 的「管理」作業,不要使用伺服器管理員 (Server Manager),或是容錯移轉叢集管理員 (Failover Cluster Manager) 來管理 S2D 運作環境,同時 S2D 運作架構並不支援 Microsoft Multipath MPIO Software Stack。
安裝 Windows Server 2016 TP2 或 TP3
因為 S2D (Storage Spaces Direct) 技術,是從 Windows Server 2016 TP2 才開始支援的特色功能,所以請為規劃的節點主機安裝 Windows Server 2016 TP2 或 TP3 版本。本次實作環境將安裝 Windows Server 2016 TP3 版本,並且也加入以 2016 TP3 版本所架設的網域控制站,當然所有的節點主機都必須加入「同一個」Windows AD 網域才行。

圖11、為節點主機安裝 Windows Server 2016 TP3 作業系統
安裝 Hyper-V 並建立虛擬交換器
本次實作環境為採用 S2D「超融合式 (Hyper-Converged)」部署模式,所以也必須在 SMB 叢集節點主機中安裝 Hyper-V 角色,並且建立虛擬交換器。請在節點主機中,開啟 PowerShell 並鍵入如下指令安裝 Hyper-V 角色,安裝角色完畢後將會重新啟動主機:Install-WindowsFeature –Name Hyper-V –IncludeManagementTools –Restart在 Windows Server 2012 R2 時有項限制,也就是採用 RDMA功能的網路卡「無法」建立虛擬交換器,也就是說 RDMA 網卡只能專用於儲存網路而已。現在,在 Windows Server 2016 中已經解除這項限制,你可以為使用 RDMA 網卡建立虛擬交換器,並且啟用「SET(Switch-Embedded Teaming)」機制。

圖 12、RDMA with Switch-Embedded Teaming 運作架構示意圖
值得注意的是,目前主流的 RDMA 協定為 RoCE (RDMA over Converged Ethernet),以及iWARP (Internet Wide Area RDMA Protocol)。若你採用的 RDMA 網卡為 RoCE的話,那麼採用的網路交換器「必須」要支援及啟用「DCB (Data Center Bridging)」才行,雖然採用 iWARP的 RDMA 網卡,無須依賴交換器的 DCB 功能,但普遍來說在支援 DCB 特色功能的網路交換器上運作,可以更容易透過 DCB 功能達到 QoS 網路流量的目的。
請在節點主機中依序鍵入下列指令,以便指派 RDMA 網卡建立虛擬交換器,同時啟用及確認是否啟用 RDMA 功能。
PS C:\> Add-VMNetworkAdapter –SwitchName S2DSwitch –Name RDMA1
PS C:\> Add-VMNetworkAdapter –SwitchName S2DSwitch –Name RDMA2
PS C:\> Enable-NetAdapterRDMA "vEthernet (RDMA1)","vEthernet (RDMA2)"
PS C:\> Get-NetAdapterRdma
Name InterfaceDescription Enabled
------- ------------------------- ----------
RDMA1 (S2DSwitch) Hyper-V Virtual Ethernet Adapter #7 True
RDMA2 (S2DSwitch) Hyper-V Virtual Ethernet Adapter #7 True
SLOT3 Mellanox ConnectX-3 Pro Ethernet Adapter True
SLOT2 Mellanox ConnectX-3 Pro Ethernet Adapter True安裝 Windows Server 角色及功能
請為每一台節點主機,鍵入如下 PowerShell 指令,以便安裝「檔案伺服器 (File-Services)」角色,以及「容錯移轉叢集 (Failover-Clustering)」功能,並包含相關管理工具。Install-WindowsFeature –Name File-Services, Failover-Clustering –IncludeManagementTools建立 SOFS 容錯移轉叢集
在建立 SOFS 容錯移轉叢集運作環境前,先進行容錯移轉叢集的驗證動作。此實作環境中,四台節點主機的電腦名稱為「S2D-Node <編號 1~4>」,因此請鍵入如下 PowerShell 指令進行叢集環境的驗證動作。Test-Cluster -Node S2D-Node1,S2D-Node2,S2D-Node3,S2D-Node4 -Include "Storage Spaces Direct",inventory,Network,"System Configuration"此外,若使用「-Include "Storage Spaces Direct"」參數時,那麼容錯移轉叢集的驗證程序便會測試共享儲存,造成叢集驗證程序發生警告或錯誤的情況。
容錯移轉叢集驗證無誤後,接著在建立容錯移轉叢集之前,請先確保每台 S2D-Node 中沒有任何硬碟被「宣告 (Claimed)」使用(例如,硬碟若被格式化過為 MBR、GPT...等),若硬碟已經被使用過的話,請先以 Diskpart 指令確認硬碟編號,然後就可以使用 Clear-Disk 的 PowerShell 來清掃硬碟中所有的內容。 (請注意!! 硬碟必須為 Online 狀態下,那麼 Clear-Disk 指令才能順利清掃硬碟內容。)
Clear-Disk –Number 1 -RemoveData -RemoveOEM //處理單顆硬碟
Clear-Disk –Number 1,2,3,4 -RemoveData -RemoveOEM //一次處理多顆硬碟執行完 Clear-Disk 動作後,硬碟的狀態應恢復到「Unknown、Not Initialized、Unallocated」才是正確狀態。請注意 !! 若硬碟未呈現正確狀態的話,稍後啟動「Software Storage Bus」機制時,將無法順利把節點主機的本機硬碟加入至儲存資源池中。

圖 13、將硬碟回到未宣告狀態,以利後續加入至儲存資源池中
前置作業都完成後,便可以放心建立容錯移轉叢集。此實作環境中叢集名稱為「S2D-FC」,而容錯移轉叢集IP位址為「192.168.250.106」,請鍵入如下 PowerShell 指令建立容錯移轉叢集。(請注意!! 執行建立容錯移轉叢集的 PowerShell 指令後,若出現「There were issues while creating the clustered role that may prevent it from starting. For more information view the report file below」警告訊息的話,可以放心忽略它。)
New-Cluster –Name S2D-FC -Node S2D-Node1,S2D-Node2,S2D-Node3,S2D-Node4 –NoStorage –StaticAddress 192.168.250.106
圖 14、建立 S2D 容錯移轉叢集
啟用 Storage Spaces Direct 機制
當容錯移轉叢集順利建立完成後,便可以使用 PowerShell 指令「啟用 Storage Spaces Direct 機制」,這個動作就是設定容錯移轉叢集啟用「Software Storage Bus」特色功能。(Get-Cluster).DASModeEnabled=1 //For Windows Server 2016 TP2
Enable-ClusterStorageSpacesDirect //For Windows Server 2016 TP3當順利啟用 Storage Spaces Direct 機制後,此時四台節點主機規劃加入儲存資源池的硬碟,便會全部消失在磁碟管理員視窗中,並且出現在「Failover Cluster Manager > Storage > Enclosures」項目內。此實作環境中,每台節點主機共有 1 顆 100 GB 的 SSD 固態硬碟以及 900 GB 的 SAS 硬碟。

圖 15、啟用 Storage Spaces Direct 機制
建立 Storage Pool、Virtual Disk、Volume
接著,就是大家所熟悉的 Storage Space 技術操作流程,也就是依序建立「Storage Pool > Virtual Disk > Volume」。值得注意的是,目前在 Windows Server 2016 技術預覽版本中,有下列相關限制:1. 必須要「停用」WBC (Write Back Cache)機制。
2. 設定 SSD 固態硬碟採用「日誌(Journal)」模式。
3. 「停用」ReFS 檔案系統中 Volume 的 Integrity Streams 功能。
4. 目前建立出來的 Volume 不支援「Resizing」功能。
建立 SOFS 高可用性角色
完成後,便可以建立 SOFS 高可用性角色,以便稍後以 UNC Path 的方式結合 SMB 3.0 協定,分享檔案資源給 Hyper-V 中的 VM 虛擬主機使用。值得注意的是,SOFS 高可用性角色的名稱請不要超過「15 個字元」。New-StorageFileServer -StorageSubSystemName S2D-WSFC -FriendlyName S2D-SOFS -HostName S2D-SOFS -Protocol SMB建立 SOFS 檔案分享資源
最後,便是建立 SOFS 檔案分享資源。值得注意的部分是,這個 SOFS 檔案分享資源的權限部分,必須要確保「Hyper-V 主機、Hyper-V 管理者帳號、Hyper-V 叢集」這三者都要具備「Full Control」的權限,否則屆時建立 VM 虛擬主機時將會因為權限問題而導致建立失敗。在加入 Hyper-V 主機及 Hyper-V 叢集名稱時,記得結尾必須加上「$」符號,舉例來說,若 Hyper-V 主機名稱為 HV-Node1 的話,那麼名稱便為「HV-Node1$」。請注意,必須採用 PowerShell 指令進行設定,若是在容錯移轉叢集管理員中進行權限設定將會發生設定錯誤的情況。

圖 16、建立 SOFS 檔案分享資源
4、結語
至此,S2D 軟體定義儲存的運作環境已經建構完成,企業及組織的IT管理人員可以嘗試將測試用途的 VM 虛擬主機,建立在 S2D 儲存資源當中,以便確認是否符合企業營運服務的運作要求。事實上,在今年 5 月份的微軟 Ignite 大會上,已經展示透過 4 台節點主機所建立的 S2D 軟體定義儲存運作環境,其磁碟效能已經高達「110 萬 IOPS」,而在今年 8 月份 Intel IDF 大會上,微軟也展示由 16 台節點主機所建立的 S2D 軟體定義儲存運作環境,每台節點主機僅用4顆硬碟便可以打造出高達「420 萬 IOPS」的磁碟效能。此外,相信在 2016 年正式推出的Windows Server 2016,將有更高的運作效能以及更簡便的設定步驟才是。